Our Take
Critique feels like the flashy, trust-the-AI option. It’s designed to let each kind of AI do what it does best, whereas Council gives you two "flavors" to review so you can have the final say about which works best. Both are good, and honestly, most users shouldn’t have to think much about models at all. We recommend trying Critique first and seeing how it feels. If you find yourself wishing you had oversight or just like seeing how things work under the hood, Council might be the better choice for you.
Microsoft is advancing deep research in the workplace with the introduction of Critique and Council, two new multi‑model capabilities now available in Researcher, Microsoft 365 Copilot’s deep research agent.
New Options for AI Research
The first announcement is Critique, a new multi‑model deep research system designed to handle complex research tasks more reliably than traditional single‑model approaches. Instead of relying on one model to do all the heavy lifting, Critique will lean on different models in roles that play to their strengths.
Previously, when you used the researcher agent for a "deep think" style task, Copilot would use GPT or Claude's deep reasoning to complete the task relying on the user to review and verify the results. Now, the default is to use a blend of the two models which enables GPT to lead the research process of planning, retrieving sources, and producing a draft while Claude is situated as an "expert reviewer" that evaluates the results using a rubric-based process.
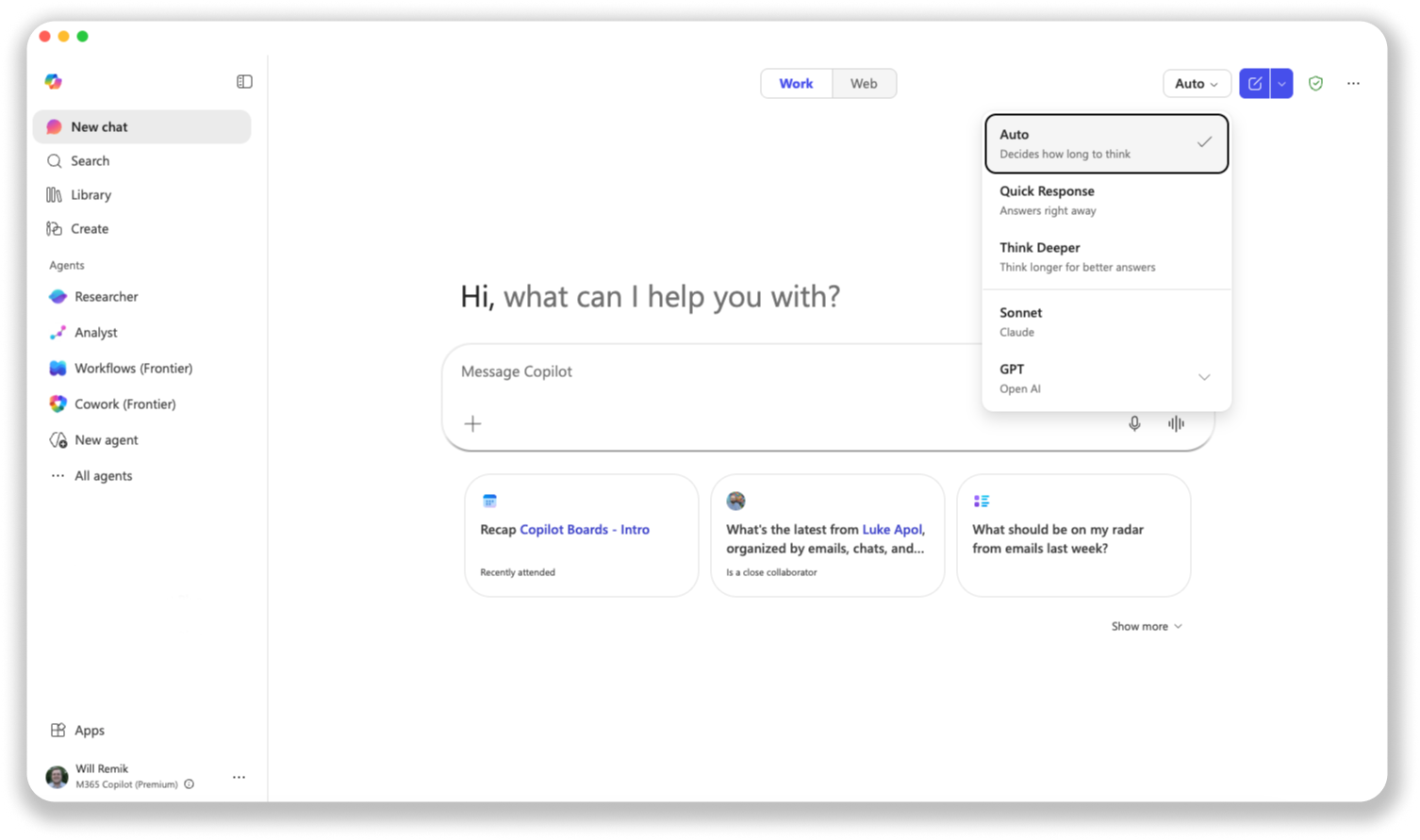
When these features are enabled for you, this is the new "Auto" selection in the model selection dropdown.
Proven Gains in Research Quality
Microsoft evaluated Critique using the DRACO benchmark (Deep Research Accuracy, Completeness, and Objectivity), a respected evaluation spanning 100 complex research tasks across 10 domains, including medicine, technology, and law.
Researcher with Critique achieved a +7.0 point improvement in aggregated DRACO scores—an increase of 13.88% over the strongest system reported in the benchmark paper. The largest gains were seen in:
- Breadth and depth of analysis
- Presentation quality
- Factual accuracy
All improvements were statistically significant, reinforcing Critique’s role as a horizontal quality layer that strengthens research across domains.
Council: Compare, Contrast, and Gain Confidence
Microsoft also introduced Council, an alternative research mode that enables the two models to run in tandem, instead of divvying out roles and responsibilities. When enabled, Council generates complete, independent research reports from both Claude and GPT.
A dedicated judge model then produces a cover letter summarizing where the models agree, where they diverge, and what unique insights each contributes. The user is also able to see the full response from the individual models and is presented with a summary table of where the models agree, and where they disagree.
Available Now in the Frontier Program
Both Critique and Council are now available through Microsoft’s Frontier program, giving organizations early access to multi‑model intelligence designed for real‑world research needs. If these features are enabled, Critique will be automatically selected and shown as “Auto,” with Council available for manual selection in the model dropdown menu.





